FAQs
INFRASTRUCTURE & APIs
Why use ZettaBlock if we already built subgraphs?
Comparing ZettaBlock to decentralized query engine solutions like The Graph, there are 4 major differences:
- Better performance.
a. High availability: ZettaBlock provides 99.99% availabilities, 20x better than subgraphs.
b. Fast indexing ETL: ZettaBlock could process 1 million rows in a few mins, 1000x faster than subgraphs.
c. API latency: ZettaBlock API's latency is ~20ms, 20x faster than subgraphs. - On-/ off-chain data silo: Data scattered across different platforms, protocols, and formats (e.g. on-chain time-series, off-chain tabular, document & blob, etc).
- Security risk: Extremely easy to hack the subgraph and manipulate query results.
- Built-in analytics and visualizations: Beyond indexing, users can write arbitrary SQL for analytics and charts directly, thanks to ZettaBlock's data lake.
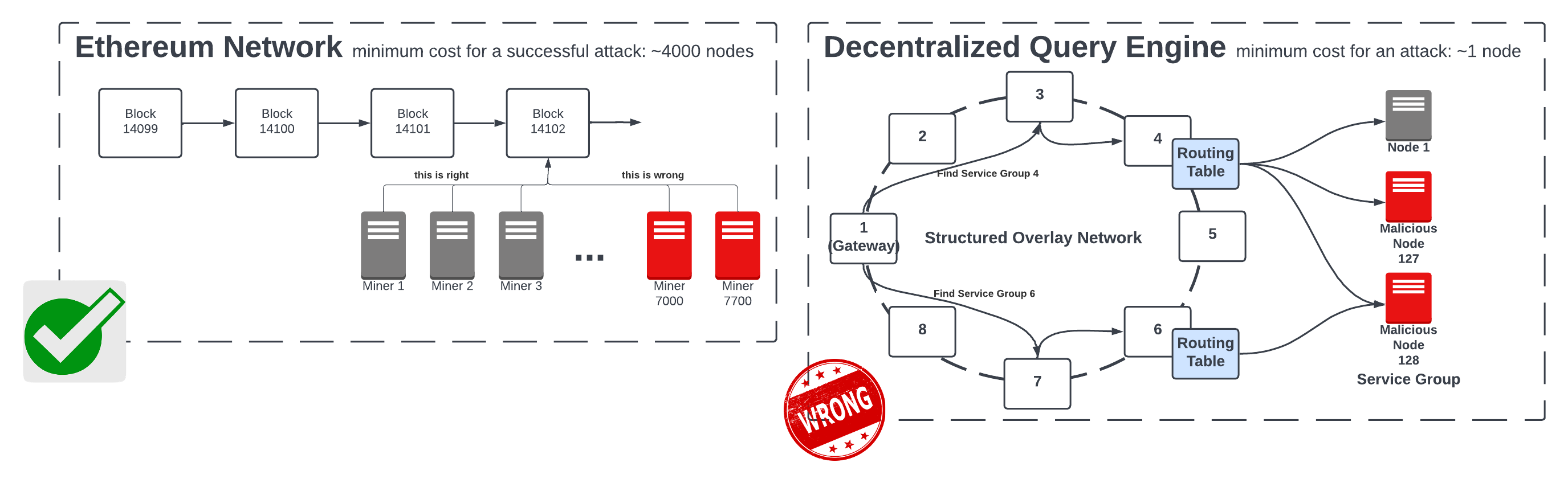
An example of how a decentralized query engine is disproportionately vulnerable to malicious nodes. The top half depicts the Ethereum network, where all compute resources are working on the same task. Thus, a malicious attack would require the majority (~4000/8000) of nodes to be malicious. For platforms like The Graph, this ratio is much lower, as different subnetworks are computing different tasks. Thus, for certain tasks (e.g., to Service Group 6), only a single malicious node would be needed to corrupt output.
Why use ZettaBlock if we already have BigQuery/ Snowflake?
Data warehouse solutions such as BigQuery and Snowflake are good for basic analytics use cases, but customers usually run into their limitations in a few common use cases, for example,
- User-facing API support: When users want to serve transformed data as a API stream to dApps/ apps, data warehouses cannot support it due to cost and performance reasons. Instead, users will turn into transactional databases. Of course, the common transactional database solutions such as Postgres can serve the purpose with the small data size. However, once the data size is beyond 1TB, users will run into DB scalability issues.
- Streaming needs: When users need to serve the latest transactions to the desired locations, the data freshness is extremely important. To achieve sub-second data freshness, users need to build and maintain a streaming architecture, which can be very difficult and costly.
- Data transformation: this is very common that the data analytics team will generate many intermediate tables for the final gold layer business logic tables, in order to reduce compute cost & SQL logic discrepancy. BigQuery, for example, cannot handle table dependency, scheduling, and orchestration for data transformation.
What is the rate limit for user queries?
For a community user, we set no hard limit on the number of queries a user can execute concurrently, as long as it's within the rate limit that is shared with all community users:
- Analytics query: max concurrency is 400.
- GraphQL API: 1000 requests per second.
For enterprise users, we provide dedicated environments with custom rate limits.
BUSINESS NEEDS
Are there specified SLAs?
SLAs are available in the Enterprise plans. For more details, please reach out to our sales team.
What’s the cost for data ingestion and storage?
No cost! Feel free to bring your own data into ZettaBlock.
What can you build using the ZettaBlock API?
The API can be used across a wide variety of Web3 use cases from custom wallets, to NFT marketplaces and dashboards to gaming. Learn how to build popular Web3 dApps using the API by checking out our use case examples as well as our catalog of prebuilt APIs which cover for the most common Web3 verticals.
How do you contact Developer Support when you're stuck?
Simply reach out to us on Discord! Our team will always be happy to help.
How does ZettaBlock accelerate time to market for developers, and what cost reductions can be expected?
ZettaBlock addresses data silos and latency challenges by providing decoded data in GraphQL or Rest API format with minimal latency. This allows developers to seamlessly integrate and utilize data, reducing time-to-market (10x faster). Additionally, developers can maximize customization by combining off-chain sources and private data, resulting in significant cost reductions (up to 99%) through streamlined and efficient data utilization.
Data
How does ZettaBlock ensure the accuracy and integrity of the data it indexes?
ZettaBlock implements a variety of approaches, first automated and then alert-based to ensure that every table meets industry-wide Data Quality standards.
How does incremental refresh work for historical blockchain data queries?
Incremental refresh works on the dataset level. When creating an API that scans -through some blockchain data to create some metrics, incremental refresh helps reduce the cost of scanning through all the data every time the query is refreshed and instead runs only through a designated amount of lookback to apply the incremental refresh. For more information please refer to this documentation page.
Can I query both on-chain and off-chain data? Can I bring my private labels?
ZettaBlock offers a variety of on and off-chain data, with the ability for users to also bring their labels in their private datasets and be able to join on-chain with off-chain data to create custom APIs and analytics for their applications.
What are the data limits for ZettaBlock's indexing and query services?
The upper bound of data that can be fetched from ZettaBlock at once is 1 GB via API, but there is a hard 5 MB limit on the UI, to help with user experience.
What support does ZettaBlock offer for indexing and querying NFT metadata and ownership history?
ZettaBlock offers erc721 latest balance tables as well as NFT metadata tables to help power any NFT-related applications.
How does ZettaBlock support the development of Web3 applications with real-time data?
ZettaBlock offers the ability to get low-latency, indexed complex queries eliminating the need for the end-user to have their own back-end + indexing solution to support their custom use case.
Can ZettaBlock provide insights into smart contract function calls and event logs for debugging purposes?
Zettablock offers a comprehensive traces table, with decoded inputs and outputs, to help developers in debugging contract-level behavior. ZettaBlock also offers contract_creations a table with all the contracts created.
To what extent does ZettaBlock decode data?
Zettablock decodes logs, transactions, and traces both using ABI as well as using event or function signatures where applicable. This enables Zettablock to offer a much higher decoding rate than otherwise possible across most smart contract events and calls.
BILLING & ACCOUNT MANAGEMENT
How is billing calculated and what pricing models are available?
Billing is based on the consumption of compute units, reflecting the amount of resources used by your operations. ZettaBlock offers a subscription pricing model to fit different needs and scales of operation. For detailed information on pricing models, please refer to the tiers directly in the app.
Are there any free tiers or trial periods available for new users to test ZettaBlock's features?
Yes, ZettaBlock offers a free tier for developers, which includes access to prebuilt APIs, running custom queries, and creating dashboards. For enterprises interested in exploring our platform, we provide an option to start a free trial tailored to your business needs. Contact our sales team for more details on enterprise trials.
How can users monitor and manage their usage to ensure they stay within budget?
Users can monitor and manage their usage through the "Usage" tab in their dashboard, which provides real-time insights into consumption. For tips on managing usage and optimizing queries to stay within budget, please refer to our usage optimization documentation.
How can users access detailed billing reports to understand their usage and charges?
Detailed billing reports can be accessed directly through your ZettaBlock account, integrated with Stripe for transparent and easy-to-understand billing details.
What payment methods does ZettaBlock accept for its services, and how can users set up recurring payments?
ZettaBlock accepts a variety of payment methods, including major credit and debit cards. Users can set up recurring payments for convenience through their account settings, ensuring uninterrupted access to our services. Wallet payments are also coming soon!
Updated 10 months ago