Incremental Data Refresh
What is incremental Refresh?
Incremental refresh is a method used to update a portion of a dataset, while preserving the existing data. It involves running two SQL statements: a transformation SQL statement to back-fill all historical data, and an incremental SQL statement to incrementally refresh the latest data.
The transformation SQL statement is used to back-fill all historical data and ensure that the data set is complete and up-to-date. This SQL statement typically updates the entire data set, including all historical data.
The incremental SQL statement is used to incrementally refresh the latest data, updating only the portions that have changed since the last refresh. This allows the data set to be updated in a more efficient and timely manner, without the need to rewrite the entire data set (and hence saving an incredible amount of compute units).
Each user has full control over what to incrementally refresh, meaning they can choose which parts of the data set they want to update. However, if the schema of the dataset is not matching, the incremental refresh will return an error. This is because the incremental refresh process relies on the schema to identify which parts of the data set have changed and need to be updated.
The logic used for incremental refresh and back-fill may be different, but the system does not correct the logic for the user. The user is responsible for ensuring that the logic used for the incremental refresh and back-fill processes is correct and meets their needs.
When should you use incremental Refresh?
It is best to use incremental refresh only when the following conditions are met:
- If incremental refresh will save costs:
- Certain APIs take very little compute units to refresh and therefore there is no need to use incremental refresh to obtain fresh data.
- The SQL has to contain at least one fact table (transactions, traces, logs, etc) or a partitioned dimension table (such as price.usd table).
- In these cases, it is possible to reduce the cost of the refresh process by only querying the data for the last 1 day or the last x hours, using incremental SQL code.
- If the SQL contains no fact/partitioned tables, then there are no good ways to reduce the costs. Incremental refresh will not help making the operations more cost-efficient. In these cases, a full scan of all historical data may be necessary.
- It is important to note that incremental refresh only works if the table is partitioned and you are only scanning a subset of the tables. This is because partitioning allows for the efficient scanning of a portion of the data set, reducing the cost and processing power required for the refresh process.
Important: All of our core facts tables (transactions,traces,logs,blocks, etc.) will contain data_creation_date as the partition key, which is derived from the block_time field. Using this partition key in your incremental SQL code, combined with a look-back period relative to your task, will allow you to cut down costs up to ~ 99%.
How to Incrementally Refresh your data?
Method 1
- First run the query logic that you're interested in
- Click Create API (The API Transformation Code should be pre-populated there)
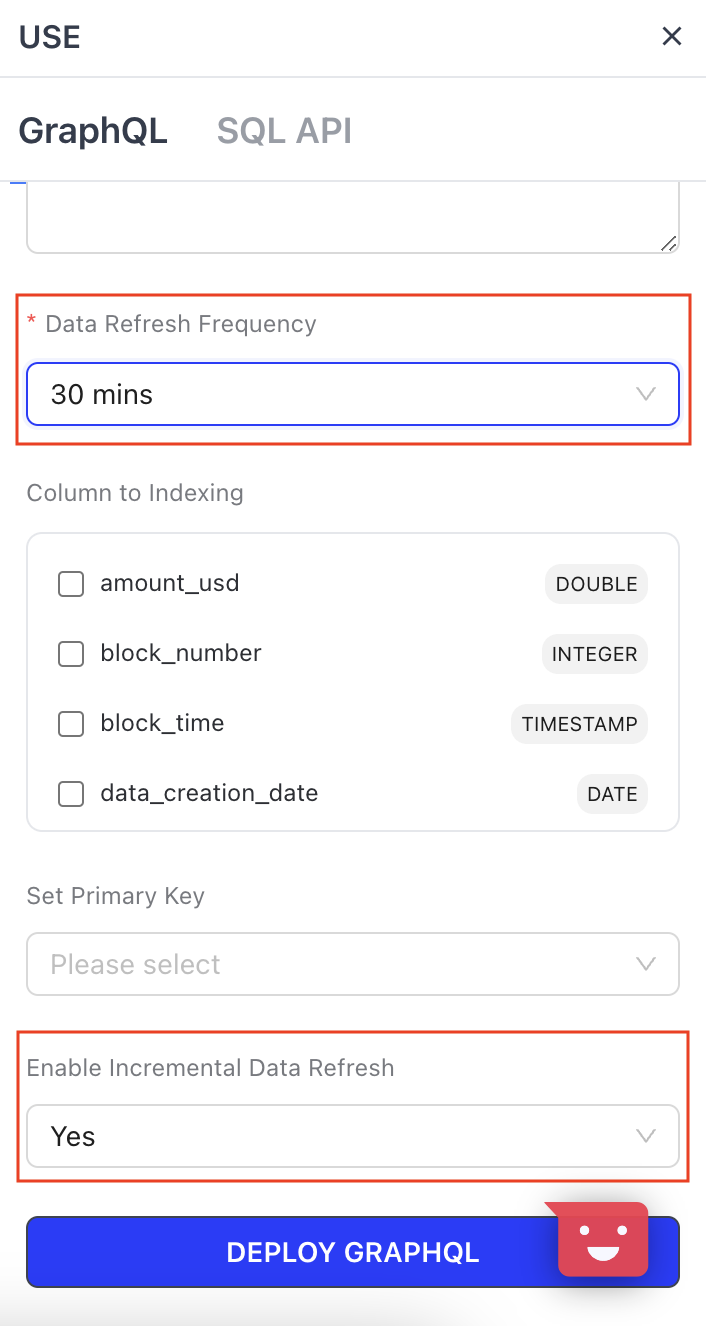
- Enable Incremental API
- Set primary key (The key in which to re-run, overwrite and forward-fill the cached data on)
- Click on Incremental SQL Code
- Add the API Transformation Code + the extra code to turn the query into an Incremental query.
Method 2
- Create New API
- Populate the API Transformation Code
- Enable Incremental API
- Set primary key (The key in which to re-run, overwrite and forward-fill the cached data on)
- Click on Incremental SQL Code
- Add the API Transformation Code + the extra code to turn the query into an Incremental query.
Examples
Example 1:
The Solana blockchain is pretty expensive to compute network metrics for, therefore a good way to ensure that you one doesn't need to re-compute for the same days historically is via creating an Incremental API.
Example API Transformation Code
WITH core as
(
SELECT
DATE(t.data_creation_date) as date_time,
COUNT(DISTINCT t.hash) as num_txns
FROM
solana_mainnet.transactions as t
WHERE
t.data_creation_date >= CURRENT_DATE - INTERVAL '30' DAY
AND t.success
GROUP BY 1
),
fees AS (
SELECT
DATE(adc.data_creation_date) as date_time,
SUM(adc.sum_of_fee) as txn_fees
FROM solana_mainnet.accounts_daily_count as adc
WHERE DATE(adc.data_creation_date) >= CURRENT_DATE - INTERVAL '30' DAY
AND adc.success
GROUP BY 1
),
prices AS (
SELECT
DATE(data_creation_date) AS date_time
, AVG(price) AS price_usd
FROM prices.usd
WHERE name = 'Solana'
AND DATE(data_creation_date) >= CURRENT_DATE - INTERVAL '30' DAY
GROUP BY 1
)
select
date_time,
core.num_txns,
fees.txn_fees*prices.price_usd as txn_fees_usd
FROM core
INNER JOIN prices USING(date_time)
INNER JOIN fees USING(date_time)
ORDER BY 1 DESCThe above query would take up ~ 904.97 Million CU to refresh every day (daily refresh).
Now let's look at the Incremental SQL Code to compare how many compute units can be saved upon each new refresh, instead of the 904.97 Million CU every day.
WITH core as
(
SELECT
DATE(t.data_creation_date) as date_time,
COUNT(DISTINCT t.hash) as num_txns
FROM
solana_mainnet.transactions as t
WHERE
t.data_creation_date >= CURRENT_DATE - INTERVAL '3' DAY
AND t.success
GROUP BY 1
),
fees AS (
SELECT
DATE(adc.data_creation_date) as date_time,
SUM(adc.sum_of_fee) as txn_fees
FROM solana_mainnet.accounts_daily_count as adc
WHERE DATE(adc.data_creation_date) >= CURRENT_DATE - INTERVAL '3' DAY
AND adc.success
GROUP BY 1
),
prices AS (
SELECT
DATE(data_creation_date) AS date_time
, AVG(price) AS price_usd
FROM prices.usd
WHERE name = 'Solana'
AND DATE(data_creation_date) >= CURRENT_DATE - INTERVAL '3' DAY
GROUP BY 1
)
select
date_time,
core.num_txns,
fees.txn_fees*prices.price_usd as txn_fees_usd
FROM core
INNER JOIN prices USING(date_time)
INNER JOIN fees USING(date_time)
ORDER BY 1 DESCThe incremental SQL query would take up ~ 904.97 Million CU to run on for the first time and then ~ 87.19 Million CU every other day (daily refresh). Compared to ~ 904.97 Million CU daily, if no incremental refresh was implemented. This would save up to ~ 90.37% cost on the 2nd refresh, and by the 7th refresh (7 days after application of incremental) you’ll be saving ~ 99.99999229360256% 🤯!
The key difference here is changing:
DATE(adc.data_creation_date) >= CURRENT_DATE - INTERVAL '30' DAY
To:
DATE(adc.data_creation_date) >= CURRENT_DATE - INTERVAL '3' DAY
Since both the prices table, accounts_daily_count and transactions table are partitioned by data_creation_date, the cost is reduced by 99%. It is recommended to optimize for all fact tables. Dimension tables like prices.usd should use partition dates as well.
Key Takeaways
This query is set to refresh every 24hrs, but to ensure that there’s no data duplication or incorrectness on when the query is being called and refreshed (see example below), we have to consider the refresh-window periods:
- Jan 1st, 11:50 pm → refresh data for Dec 31st, Jan 1st (Jan 1st has not complete)
- Jan 3rd, 12 am → refresh data Jan 2nd, 3rd (Jan 1st is never completely refreshed)
To fix this issue the user can set the lookback period on data_creation_date to be larger, such as in the example above which is 3 days compared to 2 days. This allows you to make sure there is no data missing and that everything is back-filled correctly.
Updated 10 months ago